Java 인코딩에 대해 알아야 아래의 내용이 이해된다.
Java는 String을 처리할 때 내부(메모리 상에)에서는 UTF-16 BE 인코딩으로 문자열을 저장(인코딩 할때 널 문자가 나타나지 않기 위해서)하고, 송수신에서는 직렬화가 필요한 경우 UTF-8(modified UTF-8)을 사용하며 문자열을 입/출력할 때에만 사용자가 지정한 인코딩 값 또는 운영체제의 기본 인코딩 값으로 문자열을 인코딩 한다.
결과적으로 자바 메모리에 올라갈 때의 과정을 간단히 설명하자면 다음과 같다.
이클립스의 File encoding 이 UTF-8 이라면
입력(UTF-8) -> 송수신(modified UTF-8) -> 자바 메모리 (UTF-16) -> 송수신(modified UTF-8) -> 출력(UTF-8)
즉, 운영체제 혹은 시스템에 설정되어있는 인코딩 형식으로 입력받으면 UTF-16 의 인코딩 규칙에 의해 인코딩되어 메모리에 올라가고,
출력하게 될 경우 메모리에 UTF-16 인코딩 규칙에 의해 저장되있는 값을 다시 운영체제 혹은 시스템에서 설정한 인코딩 형식으로 대응되는 문자를 출력한다.
Scanner scanner = new Scanner(System.in);여기서 System.in은 무엇일까?
BufferdReader br = new BufferedReader(new InputStreamReader(System.in));InputStreamReader는 뭐지?
이러한 궁금증을 약간이나마 해소하고자 한다.
System.in, InputStream
먼저 스트림(Stream)에 대한 간단한 이해가 필요하다.
※ 스트림(Stream)
- 파일 데이터(파일은그 시작과 끝이 있는 데이터의 스트림이다.)
- HTTP 응답 데이터(브라우저가 요청하고 서버가 응답하는 HTTP 응답 데이터도 스트림이다.)
- 키보드 입력(사용자가 키보드로 입력하는 문자열은 스트림이다.)

위 그림에서 보듯이 한 곳에서 다른곳으로의 데이터 흐름을 스트림이라고 한다.
스트림은 단방향이기 때문에 입력과 출력이 동시에 발생할 수 없다. 그렇기 때문에 용도에 따라 입력스트림, 출력스트림이 나뉜다.
자바에서 가장 기본이 되는 입력 스트림은 InputStream이다.
출력 스트림은 OutputStream이다.
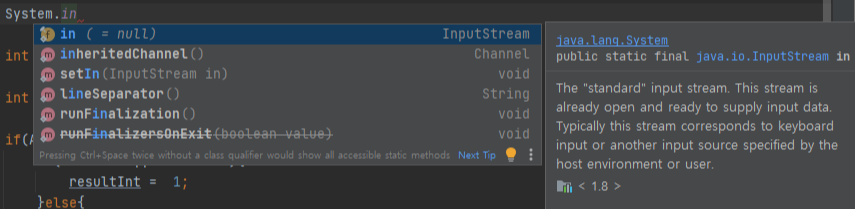
System클래스의 in이라는 필드는 InputStream의 정적 필드이다.

InputStream타입의 새 변수를 선언하고, 그 변수에 System.in을 할당시킬 수도 있다는 뜻이다.
InputStream와 System.in으로만 입력은 가능하다.
하지만 입력한 값과 전혀 다른 값이 나온다.
import java.io.IOException;
import java.io.InputStream;
public class Input_Test {
public static void main(String[] args) throws IOException {
InputStream inputStream =System.in;
int a = inputStream.read();
System.out.println(a);
}
}

InputStream.read()는 두 가지 특징이 있다.
- 입력받은 데이터는 int 형으로 저장되는데 이는 해당 문자의 시스템 또는 운영체제의 인코딩 형식의(저의 경우 UTF-8) 10진수로 변수에 저장된다.
- 1 byte만 읽는다.
InputStream은 가장 기본적인 입력스트림이다.
컴퓨터의 모든 데이터는 바이트 단위 데이터로 구성되어 있다.
데이터를 저장, 전달할때 컴퓨터에는 바이트 단위로 데이터가 저장된다.
InputStream 은 바이트 단위로 데이터를 보내며 이 InputStream 의 입력 메소드인 read()는 1 바이트 단위로 읽어 들인다. 또한 바이트 단위로 데이터를 입력받으면 입력받은 문자가 2byte 이상으로 구성되어있는 인코딩을 사용할 경우 1byte 값만 읽어들이고 나머지는 읽지 않고 스트림에만 남아있기 때문에 출력할 때는 해당 데이터의 1 Byte 에 대한 인코딩 값을 10진수로 변환한 값이 출력된다.
이렇게 바이트 단위로 주고받는 스트림을 바이트 스트림이라고도 한다.
아래처럼 바이트 배열로 입력받을 수 있다.
import java.io.IOException;
import java.io.InputStream;
public class Input_Test {
public static void main(String[] args) throws IOException {
InputStream inputStream =System.in;
byte[] bytes = new byte[10];
inputStream.read(bytes);
for (byte aByte : bytes) {
System.out.println(aByte);
}
}
}
read()메소드에 byte배열을 파라미터로 호출하면 바이트 값으로 byte배열에 저장된다.
바이트 단위로 읽기 때문에 다른 타입(int, char, ...)은 read메소드에 넣을 수 없다.

물론 실행해도 해당 문자가 아닌 운영체제의 인코딩 방식인 10진수가 나온다.
그러나, 이 방식의 가장 큰 문제점은 한글을 제대로 인식하지 못한다.
아스키코드 확장판을 보면 총 255개의 문자가 있는데 한글이 없다. ( 1 Byte 의 범위는 -128~127 이며 마지막 1bit 가 남아있는 것을 활용하여 확장한 것이 아래 128~255 범위의 문자들이다. )
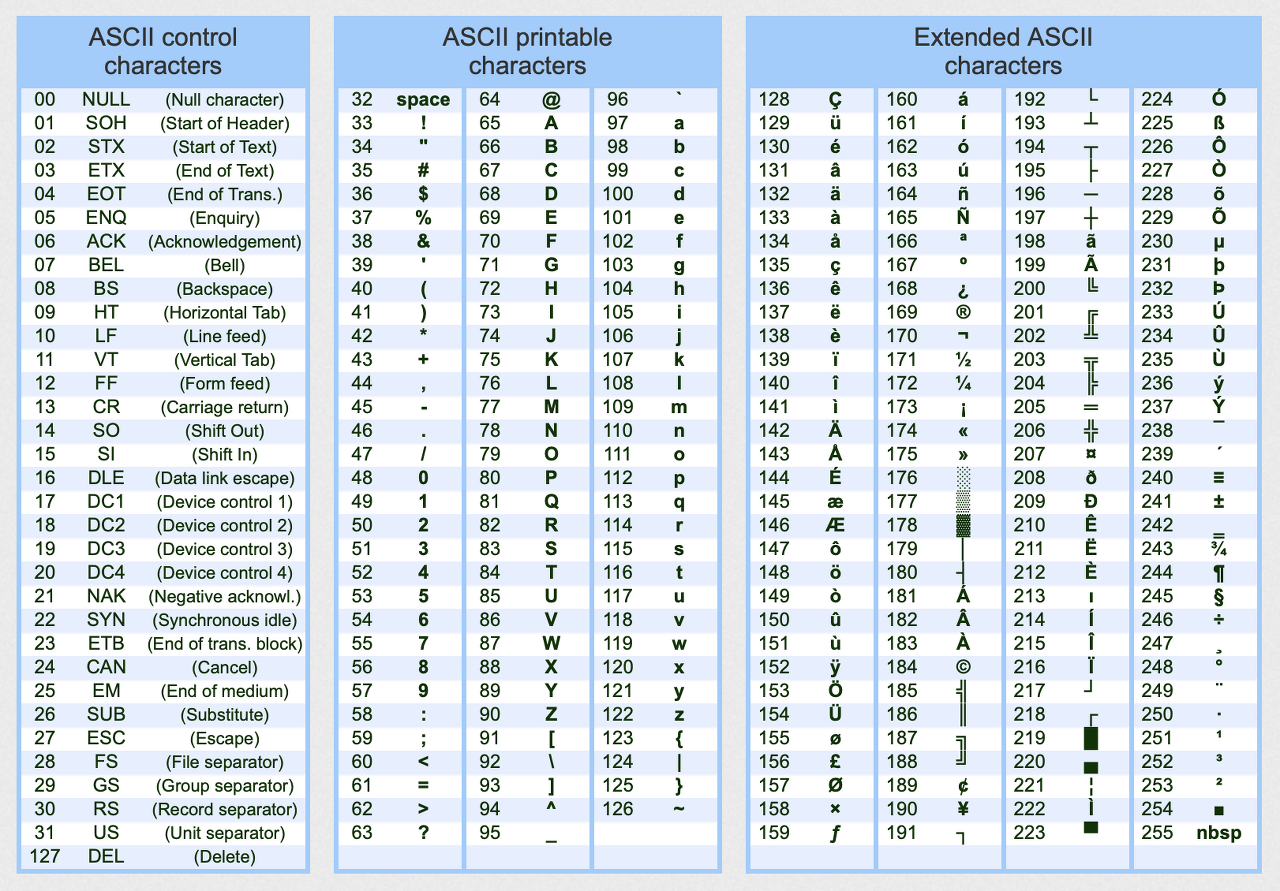
이러한 결과로 한글을 입력하면 캐스팅을 해도 아래처럼 엉뚱한 문자가 나온다.
File Encoding : UTF-8
import java.io.IOException;
import java.io.InputStream;
public class Input_Test {
public static void main(String[] args) throws IOException {
InputStream inputStream =System.in;
int IntByte = inputStream.read();
System.out.println((char)IntByte);
System.out.println(IntByte);
}
}
'가'라는 문자를 입력하자 다른 ê, 10진수로는 234값이 저장된다.
UTF-8인코딩의 경우 한글은 3Byte를 사용한다.
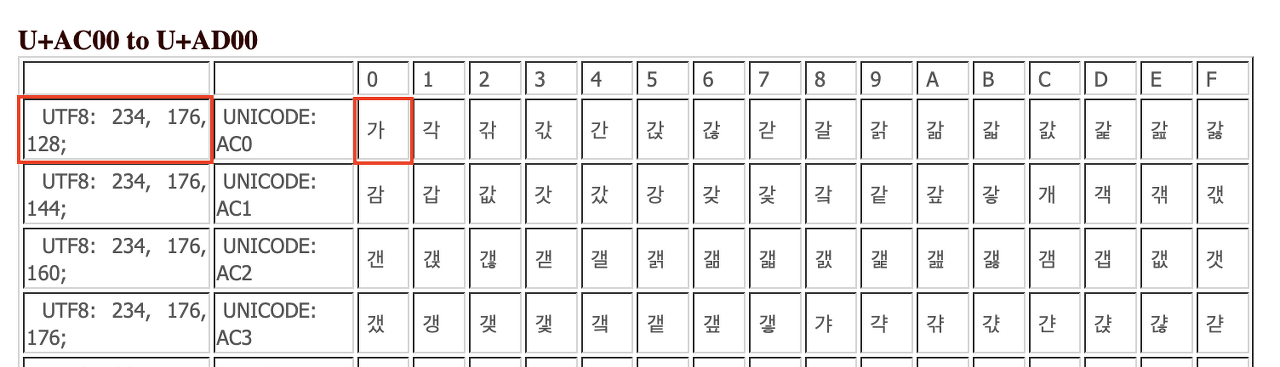
UTF-8 인코딩의 경우 3Byte로 구성되어있고 '가라는 문자는 각 1Byte씩 234, 176, 128의 구성으로 합쳐져 '가'라고 표현된다.
InputStream.read()는 1Byte 밖에 못 읽기 때문에 가장 앞의 1 Byte인 234 까지만 읽고 나머지는 바이트스트림에 남아있게 되는 것이다.
(옆에 있는 UNICODE 가 유니코드에서 코드 포인트(code point)라고 하는 값이다. 즉, '가'라는 문자가 유니코드에서는 16진수로 AC00 이라는 의미다.)
그리고 자바는 UTF-16을 사용한다.
234를 16진수로 변환하면 EA이고 자바의 인코딩 방식에 따라서 0xc3 0xaa로 변환되어 이에 대응되는 유니코드 테이블의 문자는 다음과 같다.
(자바 내부 메모리상으로는 유니코드 인코딩 규칙에 의해 2byte 길이의 이진법으로 인코딩되므로 11000011 10101010 이 저장된다.)

그래서 출력하려고 하면 11000011 110101010 에 대응되는, 즉 0xc3 0xaa 에 대응되는 문자인 ê 라는 문자가 출력되는 것이다.
정리하자면
1. UTF-8 로 입력을 받는다
2. read() 메소드는 1 byte 만 읽기 때문에 나머지 byte 는 스트림에 잔존하게 된다.
3. 읽어들인 byte 값은 메모리에 UTF-16 에 대응되는 문자의 인코딩방식으로 2진수 값이 저장한다.
4. 출력시 메모리에 저장되어있던 2진수에 대응되는 문자가 UTF-8 로 변환되어 출력된다.
출처
JAVA [자바] - 입력 뜯어보기 [Scanner, InputStream, BufferedReader]
이 글을 지금 이 시점에 써야 할까 고민을 많이 했다. 사실 자바를 그냥 다룰 줄만 아는 것에 목표를 둔다면 이 글이 무의미할 수도 있다. 그러나 자바에 대해 조금이라도 관심이 있고 더 배우고
st-lab.tistory.com
'Java > 기초' 카테고리의 다른 글
| [Java] LocalDateTime (0) | 2021.08.30 |
|---|---|
| [Java] Optional (0) | 2021.08.25 |
| [Java] 스트림(Stream) (0) | 2021.08.10 |
| [Java] 람다식(Lambda expression) (0) | 2021.08.10 |
| [Java] 쓰레드(Thread) - 2/2 (동기화) (0) | 2021.08.09 |